Create a Program to Implement Pytorch in Python Assignment Solution

- Instructions
- Objective
- Requirements and Specifications
Instructions
Objective
If you're looking to write a Python assignment, one interesting task could be to create a program that implements PyTorch in Python. PyTorch is a popular open-source machine learning library known for its dynamic computational graph and GPU acceleration capabilities. Writing a Python assignment that involves implementing PyTorch would not only help students learn about neural networks and deep learning but also give them hands-on experience with a powerful framework for machine learning tasks..
Requirements and Specifications
Generate sentences using PyTorch trained model on Wikipedia text
Python
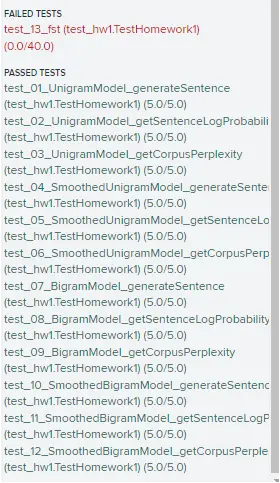
Source Code
# -*- coding: utf-8 -*-
"""hwk1.ipynb
Automatically generated by Colaboratory.
Original file is located at
https://colab.research.google.com/drive/1mlnBydfeajSWRWl9mXTsZw5eEbQlmCIt
# CS 447 Homework 1 $-$ Language Models & Morphological Transduction
In this homework we will study some traditional appraoches to a few natural language tasks. First, you will build some n-gram language models on a corpus of Wikipedia articles, and then you will design a finite-state transducer for verb conjugation in Spanish.
This notebook is designed to be run in Google Colab. Navigate to colab.research.google.com and upload this notebook. Then follow the instructions in the notebook to do the assignent.
To run the notebook, you will need to connect to a Runtime. For this homework, all you need is a CPU. You can change the runtime by going to Runtime > Change runtime type and selecting None in the Hardware Accelerator field. We encourage you to disconnect from the runtime when you are not using it, as Google Colab can limit your resources if you overuse them.
You can read more about Google Colab at https://research.google.com/colaboratory/faq.html.
#Part 1: Language Models [60 points]
Here, you will train some n-gram language models on WikiText-2, a corpus of high-quality Wikipedia articles. The dataset was originally introduced in the following paper: https://arxiv.org/pdf/1609.07843v1.pdf. A raw version of the data can easily be viewed here: https://github.com/pytorch/examples/tree/master/word_language_model/data/wikitext-2.
Unfortunately, you have to install the torchdata package on the Colab machine in order to access the data. To do this, run the cell below (you may need to click the "Restart Runtime" button when it finishes). You will have to do this every time you return to work on the homework.
"""
!pip install torchdata
# Constants (feel free to use these in your code, but do not change them)
START = "" # Start-of-sentence token
END = "" # End-of-sentence-token
UNK = "" # Unknown word token
"""## Preprocessing the Data
To make your models more robust, it is necessary to perform some basic preprocessing on the corpora. You do not need to edit this code.
* Sentence splitting: In this homework, we are interested in modeling individual sentences, rather than longer chunks of text such as paragraphs or documents. The WikiTest dataset provides paragraphs; thus, we provide a simple method to identify individual sentences by splitting paragraphs at punctuation tokens (".", "!", "?").
* Sentence markers: For both training and testing corpora, each sentence must be surrounded by a start-of-sentence (``) and end-of-sentence marker (`/s`). These markers will allow your models to generate sentences that have realistic beginnings and endings.
* Unknown words: In order to deal with unknown words in the test corpora, all words that do not appear in the vocabulary must be replaced with a special token for unknown words (``) before estimating your models. The WikiText dataset has already done this, and you can read about the method in the paper above. When unknown words are encountered in the test corpus, they should be treated as that special token instead.
We provide you with preprocessing code here, and you should not modify it.
After the preprocessing, you may assume that all words in the test set appear in the training set, as this code has already replaced the unseen tokens with ``.
"""
### DO NOT EDIT THIS CELL ###
import torchtext
import random
import sys
def preprocess(data, vocab=None):
final_data = []
lowercase = "abcdefghijklmnopqrstuvwxyz"
for paragraph in data:
paragraph = [x if x != '' else UNK for x in paragraph.split()]
if vocab is not None:
paragraph = [x if x in vocab else UNK for x in paragraph]
if paragraph == [] or paragraph.count('=') >= 2: continue
sen = []
prev_punct, prev_quot = False, False
for word in paragraph:
if prev_quot:
if word[0] not in lowercase:
final_data.append(sen)
sen = []
prev_punct, prev_quot = False, False
if prev_punct:
if word == '"':
prev_punct, prev_quot = False, True
else:
if word[0] not in lowercase:
final_data.append(sen)
sen = []
prev_punct, prev_quot = False, False
if word in {'.', '?', '!'}: prev_punct = True
sen += [word]
if sen[-1] not in {'.', '?', '!', '"'}: continue # Prevent a lot of short sentences
final_data.append(sen)
vocab_was_none = vocab is None
if vocab is None:
vocab = set()
for i in range(len(final_data)):
final_data[i] = [START] + final_data[i] + [END]
if vocab_was_none:
for word in final_data[i]:
vocab.add(word)
return final_data, vocab
def getDataset():
dataset = torchtext.datasets.WikiText2(root='.data', split=('train', 'valid'))
train_dataset, vocab = preprocess(dataset[0])
test_dataset, _ = preprocess(dataset[1], vocab)
return train_dataset, test_dataset
train_dataset, test_dataset = getDataset()
"""Run the next cell to see 10 random sentences of the training data."""
if __name__ == '__main__':
for x in random.sample(train_dataset, 10):
print (x)
"""## The LanguageModel Class
You will implement 4 types of language models: a unigram model, a smoothed unigram model, a bigram model, and a smoothed bigram model. Each of the models is worth 15 points and extends the following base class. You do not need to implement anything in this class; you will instead implement each of the following methods in the relevant subclass:
* `__init__(self, trainCorpus)`: Train the language model on `trainCorpus`. This will involve calculating relative frequency estimates according to the type of model you're implementing.
* `generateSentence(self)`: [5 points] Return a sentence that is generated by the language model. It should be a list of the form [, w(1), ..., w(n), ], where each w(i) is a word in your vocabulary (including but exlcuding and ). You may assume that starts each sentence (with probability $1$). The following words w(1), ... , w(n), are generated according to your language model's distribution. Note that the number of words n is not fixed; instead, you should stop the sentence as soon as you generate the stop token .
* `getSentenceLogProbability(self, sentence)`: [5 points] Return the logarithm of the probability of sentence, which is again a list of the form [, w(1), ..., w(n), ]. You should use the natural logarithm $-$ that is, the base-e logarithm. See the note below about performing your calculations in log space.
* `getCorpusPerplexity(self, testCorpus)`: [5 points] You need to compute the perplexity (normalized inverse log probability) of `testCorpus` according to your model. For a corpus $W$ with $N$ words and a bigram model, Jurafsky and Martin tells you to compute perplexity as follows:
$$Perplexity(W) = \Big [ \prod_{i=1}^N \frac{1}{P(w^{(i)}|w^{(i-1)})} \Big ]^{1/N}$$
Implementation Hint: In order to avoid underflow, you will likely need to do all of your calculations in log-space. That is, instead of multiplying probabilities, you should add the logarithms of the probabilities and exponentiate the result:
$$\prod_{i=1}^N P(w^{(i)}|w^{(i-1)}) = \exp\Big (\sum_{i=1}^N \log P(w^{(i)}|w^{(i-1)}) \Big ) $$
Using this property should help you in your implementation of `generateSentence(self)` and `getCorpusPerplexity(self, testCorpus)`.
Feel free to implement helper methods as you wish (either in the base class or in the subclases). But be sure not to change the function signatures of the provided methods (i.e. the function and argument names), or else the autograder will fail.
"""
import math
import random
from collections import defaultdict
class LanguageModel(object):
def __init__(self, trainCorpus):
'''
Initialize and train the model (i.e. estimate the model's underlying probability
distribution from the training corpus.)
'''
### DO NOT EDIT ###
return
def generateSentence(self):
'''
Generate a sentence by drawing words according to the model's probability distribution.
Note: Think about how to set the length of the sentence in a principled way.
'''
### DO NOT EDIT ###
raise NotImplementedError("Implement generateSentence in each subclass.")
def getSentenceLogProbability(self, sentence):
'''
Calculate the log probability of the sentence provided.
'''
### DO NOT EDIT ###
raise NotImplementedError("Implement getSentenceProbability in each subclass.")
def getCorpusPerplexity(self, testCorpus):
'''
Calculate the perplexity of the corpus provided.
'''
### DO NOT EDIT ###
raise NotImplementedError("Implement getCorpusPerplexity in each subclass.")
def printSentences(self, n):
'''
Prints n sentences generated by your model.
'''
### DO NOT EDIT ###
for i in range(n):
sent = self.generateSentence()
prob = self.getSentenceLogProbability(sent)
print('Log Probability:', prob , '\tSentence:',sent)
"""## TODO: Unigram Model [15 points]
Here, you will implement each of the 4 functions described above for an unsmoothed unigram model. The probability distribution of a word is given by $\hat P(w)$.
Hints:
* You should use a dictionary to map tokens to their unigram counts.
* Since you never want to generate the start-of-sentence token ``, you should not include it in your counts.
* In general, avoid checking for membership in a list (i.e. avoid `x in lst`). Instead, use sets or dictionaries for this purpose $-$ membership checks are much faster on these data structures.
* Do not modify the training or test corpora by using `.append(...)` or `.pop(...)` on them. This will cause unexpected behavior in the autograder tests, which do not expect you to be changing the data.
"""
class UnigramModel(LanguageModel):
def __init__(self, trainCorpus):
### TODO ###
elf.counts = defaultdict(float)
self.total = 0.0
self.train(trainCorpus)
def generateSentence(self):
### TODO ###
sentence = []
word = START
while word != END:
sentence.append(word)
word=self.draw()
sentence.append(END)
return sentence
def getSentenceLogProbability(self, sentence):
### TODO ###
prob=1.0
for word in sentence[1:]:
prob*=self.prob(word)
return math.log(prob)
tCorpusPerplexity(self, testCorpus):
### TODO ###
words = [word for sentence in testCorpus for word in sentence[1:]]
log_sum = 0.0
for word in words:
P = self.prob(word)
if P!= 0:
log_sum += math.log(self.prob(word))
return math.exp(log_sum /-len(words))
""We provide you with a testing function that uses very simple training & test corpora (you could compute probability/perplexity by hand if you wanted to). This is just a sanity check $-$ passing this test does not guarantee you a perfect score in the autograder; this is simply to help you debug your model."""
def sanityCheck(model_type):
assert model_type in {'unigram', 'bigram', 'smoothed-unigram', 'smoothed-bigram'}
# Read in the test corpus
train_corpus = ["By the Late Classic , a network of few ( few ) linked various parts of the city , running for several kilometres through its urban core .",
"Few people realize how difficult it was to create Sonic 's graphics engine , which allowed for the incredible rate of speed the game 's known for ."]
test_corpus = ["Classic few parts of the game allowed for few incredible city .",
"Few realize the difficult network , which linked the game to Sonic ."]
train_corpus, _ = preprocess(train_corpus)
test_corpus, _ = preprocess(test_corpus)
sentence = preprocess(["Sonic was difficult ."])[0][0]
# These are the correct answers (don't change them!)
if model_type == "unigram":
senprobs = [-19.08542845, -114.5001481799, -108.7963657053, -53.6727664115, -55.4645258807]
trainPerp, testPerp = 41.3308239726, 38.0122981569
model = UnigramModel(train_corpus)
elif model_type == "smoothed-unigram":
senprobs = [-19.0405293515, -115.3479413049, -108.9114348746, -54.8190029616, -55.8122547346]
trainPerp, testPerp = 41.9994393615, 39.9531928383
model = SmoothedUnigramModel(train_corpus)
elif model_type == "bigram":
senprobs = [-float('inf'), -10.3450917073, -9.2464794186, -float('inf'), -float('inf')]
trainPerp, testPerp = 1.3861445461, float('inf')
model = BigramModel(train_corpus)
elif model_type == "smoothed-bigram":
senprobs = [-16.355820202, -76.0026113319, -74.2346475108, -47.2885760372, -51.2730261907]
trainPerp, testPerp = 12.2307627397, 26.7193157699
model = SmoothedBigramModelAD(train_corpus)
print("--- TEST: generateSentence() ---")
modelSen = model.generateSentence()
senTestPassed = isinstance(modelSen, list) and len(modelSen) > 1 and isinstance(modelSen[0], str)
if senTestPassed:
print ("Test generateSentence() passed!")
else:
print ("Test generateSentence() failed; did not return a list of strings...")
print("\n--- TEST: getSentenceLogProbability(...) ---")
sentences = [sentence, *train_corpus, *test_corpus]
failed = 0
for i in range(len(sentences)):
sen, correct_prob = sentences[i], senprobs[i]
prob = round(model.getSentenceLogProbability(sen), 10)
print("Correct log prob.:", correct_prob, '\tYour log prob.:', prob, '\t', 'PASSED' if prob == correct_prob else 'FAILED', '\t', sen)
if prob != correct_prob: failed+=1
if not failed:
print ("Test getSentenceProbability(...) passed!")
else:
print("Test getSentenceProbability(...) failed on", failed, "sentence" if failed == 1 else 'sentences...')
print("\n--- TEST: getCorpusPerplexity(...) ---")
train_perp = round(model.getCorpusPerplexity(train_corpus), 10)
test_perp = round(model.getCorpusPerplexity(test_corpus), 10)
print("Correct train perp.:", trainPerp, '\tYour train perp.:', train_perp, '\t', 'PASSED' if trainPerp == train_perp else 'FAILED')
print("Correct test perp.:", testPerp, '\tYour test perp.:', test_perp, '\t', 'PASSED' if testPerp == test_perp else 'FAILED')
train_passed, test_passed = train_perp == trainPerp, test_perp == testPerp
if train_passed and test_passed:
print("Test getCorpusPerplexity(...) passed!")
else:
print("Test getCorpusPerplexity(...) failed on", "the training corpus and the testing corpus..." if not train_passed and not test_passed else "the testing corpus..." if not test_passed else "the training corpus...")
if __name__=='__main__':
sanityCheck('unigram')
"""Now, you can train your model on the full WikiText corpus, and evaluate it on the held-out test set."""
def runModel(model_type):
assert model_type in {'unigram', 'bigram', 'smoothed-unigram', 'smoothed-bigram'}
# Read the corpora
if model_type == 'unigram':
model = UnigramModel(train_dataset)
elif model_type == 'bigram':
model = BigramModel(train_dataset)
elif model_type == 'smoothed-unigram':
model = SmoothedUnigramModel(train_dataset)
else:
model = SmoothedBigramModelAD(train_dataset)
print("--------- 5 sentences from your model ---------")
model.printSentences(5)
print ("\n--------- Corpus Perplexities ---------")
print ("Training Set:", model.getCorpusPerplexity(train_dataset))
print ("Testing Set:", model.getCorpusPerplexity(test_dataset))
if __name__=='__main__':
runModel('unigram')
"""## TODO: Smoothed Unigram Model [15 points]
Here, you will implement each of the 4 functions described above for a unigram model with Laplace (add-one) smoothing. The probability distribution of a word is given by $P_L(w)$. This type of smoothing takes away some of the probability mass for observed events and assigns it to unseen events.
In order to smooth your model, you will need the number of words in the corpus, $N$, and the number of word types, $S$. The distinction between these is meaningful: $N$ indicates the number of word instances, where $S$ refers to the size of our vocabulary. For example, the sentence the cat saw the dog has four word types (the, cat, saw, dog), but five word tokens (the, cat, saw, the, dog). The token the appears twice in the sentence, but they share the same type the.
If $c(w)$ is the frequency of $w$ in the training data, you can compute $P_L(w)$ as follows:
$$P_L(w)=\frac{c(w)+1}{N+S}$$
Hints:
* You may find it convenient to make your `SmoothedUnigramModel` inherit your `UnigramModel`, and then override the function(s) that need to be changed.
"""
class SmoothedUnigramModel(LanguageModel):
def __init__(self, trainCorpus):
### TODO ###
self.counts = defaultdict(float)
self.total = 0.0
self.train(trainCorpus)
def generateSentence(self):
### TODO ###
sentence = []
word = START
while word != END:
sentence.append(word)
word=self.draw()
sentence.append(END)
return sentence
def getSentenceLogProbability(self, sentence):
### TODO ###
prob=1.0
for word in sentence[1:]:
prob*=self.prob(word)
return math.log(prob) if prob != 0 else -math.inf
def getCorpusPerplexity(self, testCorpus):
### TODO ###
words = [word for sentence in testCorpus for word in sentence[1:]]
log_sum = 0.0
for word in words:
P = self.prob(word)
if P!= 0:
log_sum += math.log(self.prob(word))
return math.exp(log_sum/-len(words))
if __name__=='__main__':
sanityCheck('smoothed-unigram')
if __name__=='__main__':
runModel('smoothed-unigram')
"""## TODO: Bigram Model [15 points]
Here, you will implement each of the 4 functions described above for an unsmoothed bigram model. The probability distribution of a word is given by $\hat P(w'|w)$. Thus, the probability of $w_i$ is conditioned on $w_{i-1}$.
Hints:
* You should use a dictionary of dictionaries to store your bigram counts. That is, the outer dictionary should map $w$ to another dictionary that maps $w'$ to the number of times $w'$ occurs after $w$.
* Do not attempt to iterate over all possible bigrams in your voabulary: only store bigrams that actually occur in your training data. You will run into timeout or out-of-memory issues if you attempt to enumerate all bigrams.
* Similarly, avoid nested loops over the training data.
"""
class BigramModel(LanguageModel):
def __init__(self, trainCorpus):
### TODO ###
self.priors = defaultdict(lambda : defaultdict(float))
self.total = defaultdict(float)
self.train(trainCorpus)
def generateSentence(self):
### TODO ###
sentence = [START]
word = self.draw(START)
while word != END:
sentence.append(word)
word=self.draw(word)
sentence.append(END)
return sentence
def getSentenceLogProbability(self, sentence):
### TODO ###
prior=START
prob=1.0
for word in sentence[1:]:
prob*=self.prob(word, prior)
prior=word
return math.log(prob) if prob != 0 else -math.inf
def getCorpusPerplexity(self, testCorpus):
### TODO ###
prior=START
words = (word for sentence in testCorpus for word in sentence)
next(words)
word_len=0
log_sum = 0.0
for word in words:
try:
log_sum += (math.log(self.prob(word, prior)) if self.prob(word, prior) != 0 else math.inf)#math.log(self.prob(word, prior))
word_len+=1
except:
pass#Underflow on
prior=word
return (math.exp(log_sum/-word_len) if log_sum != math.inf else math.inf)
if __name__=='__main__':
sanityCheck('bigram')
if __name__=='__main__':
runModel('bigram')
"""## TODO: Smoothed Bigram Model [15 points]
Here, you will implement each of the 4 functions described above for a bigram model with absolute discounting. The probability distribution of a word is given by $P_{AD}(w’|w)$.
In order to smooth your model, you need to compute a discounting factor $D$. If $n_k$ is the number of bigrams $w_1w_2$ that appear exactly $k$ times, you can compute $D$ as:
$$D=\frac{n_1}{n_1+2n_2}$$
For each word $w$, you then need to compute the number of bigram types $ww’$ as follows:
$$S(w)=|\{w’\mid c(ww’)>0\}|$$
where $c(ww’)$ is the frequency of $ww’$ in the training data. In other words, $S(w)$ is the number of unique words that follow $w$ at least once in the training data.
Finally, you can compute $P_{AD}(w’|w)$ as follows:
$$P_{AD}(w’|w)=\frac{\max \big (c(ww’)-D,0\big )}{c(w)}+\bigg (\frac{D}{c(w)}\cdot S(w) \cdot P_L(w’)\bigg )$$
where $c(w)$ is the frequency of $w$ in the training data and $P_L(w’)$ is the Laplace-smoothed unigram probability of $w’$.
"""
class SmoothedBigramModelAD(LanguageModel):
def __init__(self, trainCorpus):
self.double_count = defaultdict(float)
self.single_count = defaultdict(float)
self.following = defaultdict(set)
self.number_of_words = 0.0
self.number_of_words_exclude_start_and_end = 0.0;
self.size_of_vocab_exclud_start_and_end = 0.0;
self.pair_once = 0.0
self.pair_twice = 0.0
self.D = 0.0
self.total_pair_sum = 0.0
self.corpusLen = len(corpus)
self.corpus = corpus
self.counts = defaultdict(float)
self.total = 0.0
def generateSentence(self):
### TODO ###
def generateSentence(self):
sent = [START]
prevword = START
while(1):
newword = self.draw(prevword)
sent.append(newword)
if newword == END or not newword:
break
prevword = newword
return sent
def getSentenceLogProbability(self, sentence):
### TODO ###
raw_result = 0
prevword = START
for word in sen[1:]:
tempprob = self.prob(word= word, prevword=prevword)
raw_result += math.log(tempprob)
prevword = word
return raw_result
def getCorpusPerplexity(self, testCorpus):
### TODO ###
logsum = 0
for sen in corpus:
logsum += self.getSentenceLogProbability(sen)
return math.exp(-logsum / self.total_pair_sum)
if __name__=='__main__':
sanityCheck('smoothed-bigram')
if __name__=='__main__':
runModel('smoothed-bigram')
"""## Food for Thought
We provide you some questions to think about. You do not need to answer these questions, but we encourage you to give them some thought.
When generating sentences with the unigram model, what controls the length of the generated sentences? How does this differ from the sentences produced by the bigram models?
Consider the probability of the generated sentences according to your models. Do your models assign drastically different probabilities to the different sets of sentences? Why do you think that is?
Look back at the sentences generated using your models. In your opinion, which model produces better / more realistic sentences?
For each of the four models, which test corpus has the highest perplexity? Why?
Why do you think it might be a bad idea to use Laplace (add-one) smoothing for a bigram model? How does the absolute discounting method help?
# Part 2: Finite State Transducers [40 points]
Here, you will implement a finite state transducer (FST), which transduces the infinitive form of Spanish verbs to the preterite (past tense) form in the 3rd person singular. You will be graded according to how well your transducer performs on a hidden test dataset.
Run the cell below to pull the data you can use to develop your FST.
## Provided Code
We provide you with a class FST, which is a module for constructing and evaluating FST's. You shouldn't modify any of this code. Here is a description of the most useful methods of this module:
* `FST(self, initialStateName)`: Instantiate an FST with an initial (non-accepting) state named `initialStateName`
* `addState(self, name, isFinal=False)`: Add a state `name` to the FST; by default, `isFinal=False` and so the state is not an accepting state.
* `addTransition(self, inStateName, inString, outString, outStateName)`: Add a transition between state `inStateName` and state `outStateName`, where both of these states already exist in the FST. The FST can traverse this transition after reading `inString`, and outputs `outString` when it does so.
* `addSetTransition(self, inStateName, inStringSet, outStateName)`: Add a transition between state `inStateName` and state `outStateName` for each character in `inStringSet`. For each transition, the FST outputs the same character it reads.
The cell also contains a method to read the data and a scoring function that you will call in the "Test your FST" section.
Do not edit any of the code in this cell!
"""
### DO NOT EDIT THIS CELL ###
import os
import pandas as pd
from tabulate import tabulate
pdtabulate=lambda df:tabulate(df,headers='keys',tablefmt='psql', showindex=False)
def readVerbFile(file):
url='https://drive.google.com/u/0/uc?id=18x48rbiNvWoB54wccc635IVkOHzIfS6K&export=download'
df = pd.read_csv(url, header=None)
return df.values.tolist()
verbs = readVerbFile('verbsList.csv')
Python
Python
Python
Python
Python
Python
Python
Python
Python
Python
Python
Python
Python
Python
Python
Python
Python
Python
Python
Python
Our Popular Services
Explore our curated collection of programming assignment samples at ProgrammingHomeworkHelp.com. Our samples cover diverse topics such as Java, Python, C++, algorithms, and more. Each example provides clear solutions and valuable insights to help students understand and apply programming concepts effectively. Enhance your learning experience with our comprehensive resources.